Behavioral autocapture for product analytics: Heap vs. Amplitude vs. Pendo

Capturing and analyzing behavioral data is critical to understanding and optimizing your user experiences. But what’s the best way to go about it?
Manually tagging events is time- and resource-consuming, vulnerable to human error, and demands that you pick the right events to track in advance.
Ultimately, manual tagging captures only a partial picture of your behavioral data. To fully understand your user experiences (and for your AI algorithms to make informed decisions) you need the complete picture.
This is why businesses are increasingly turning to analytics solutions that automatically capture behavioral data, which (in theory, at least) solves many of the issues that come with manual tagging.
But, if you’re shopping for an autocapture-enabling solution, you need to be cautious. The ‘autocapture’ capability offered by many solutions may fall far short of what your business actually needs.
To help you decide what sort of autocapture will work for you, we’re going to compare the autocapture feature offered by Heap (that’s us 👋) to that offered by 2 popular alternatives: Amplitude and Pendo.
In this article, we’ll run through
What autocapture is and why you need it
Where manual tagging falls short (but why it’s still important)
The pros and cons of Amplitude, Pendo, and Heap’s autocapture capabilities
What is autocapture and why do you need it?
Autocapture enables businesses to automatically capture the digital interactions of its customers, including clicks, swipes, form submissions, and page views.
Setup can be as simple as inputting a single line of code, but that depends on the solution you’re using and the proportion of events you want to automatically capture.
As you’ll soon see, some solutions automatically capture only certain events by default, requiring you to manually tag everything else.
But that isn’t ‘true’ autocapture. With Heap, everything is tracked from the moment of install. This ensures your underlying behavioral dataset is complete, and can be retroactively analyzed with 100% reliability.
This is critical for your analytics, especially in a world where AI analytics is giving businesses a competitive edge. Remember: your AI is only as smart as the data underlying it. If your AI isn’t working from a complete picture of user behavior, you have non-smart intelligence. (And that’s not so smart.)
Autocapture vs. manual tagging

Manual tagging involves deciding which behavioral events you want to track in advance, then having an engineer add tracking code to those events so they can be analyzed.
Manual tagging certainly has its place, allowing you to enrich your event data with metadata to provide additional context. But it doesn’t have to be your foundation.
Relying exclusively on manual tagging in this day and age is a mistake. Manual tagging has 3 big flaws which autocapture (at its best) corrects for, giving you the speed, completeness of data, and flexibility to enable product decisions that move as fast your roadmap.
#1 With manual tagging you miss events
When putting together a tagging plan, you may choose not to track certain events that later turn out to be important—or miss them altogether.
And who could blame you? There are so many potentially trackable events, and while you can make a good guess, it’s impossible to know in advance which of those events are going to turn out to be important.
(If you can predict this with 100% accuracy, please get in touch with us before the next lotto draw.)
With autocapture, you don’t miss anything. As we’ll show below, analytics solutions differ in terms of how comprehensively they capture data by default.
That said, if you have Heap, every behavioral event is captured. This means never having to say “I don’t know” when it comes to your behavioral data.
#2 With manual tagging you’ll need to re-tag as your product evolves
Without autocapture, you’ll have to add tracking code as you add new pages, features, and elements to your product.
Forget to do this and all customer interactions with those new elements will be lost. This creates what we call a ‘data blackout’—a period of time during which no data is collected, which, given how important your users’ first interactions with new features are, is far from ideal.
Even if you don’t forget, tagging every single update is a tedious process to go through, and that tedium could even disincentivize evolution.
With autocapture, no new tags are required. Every event is captured, old or new. Plus, if you’re changing an existing event, a good solution will alert you to combine the ‘new’ and ‘old’ events so all the relevant behavioral data falls under the same umbrella.
#3 Manual tagging wastes time and creates analytics bottlenecks
Manually tagging events and maintaining tracking code takes time—time your engineers could spend far more productively.
Plus, with the inevitable backlog that a deluge of tagging requests creates, you might have to wait weeks (or even months) for the insights you’re looking for.
With autocapture, your engineers are freed up to build stuff instead of tagging stuff—and you get the insights you need within minutes.
Autocapture
Autocapture is the best way to go for making sure all of your behavioral data is captured, all of the time, without having a crippling impact on your engineering team.
However, this doesn’t mean that manually tagging data should be discarded.
Every business is unique, and it’s important for data mature companies to have the flexibility to define events the way they want and feel comfortable with.
Plus, while autocapture can capture every behavioral event in your user journeys, this doesn’t mean it captures everything that’s relevant to your analytics.
There’s plenty of data relating to your users and to their behavior that adds important context but which is simply too sensitive to be captured by default. For example: data that reveals the user’s role or name, or the dollar value of an event.
This is why the best analytics solutions offer both autocapture and manual tagging, so you can enrich your behavioral data with backend and client-side data (and vice versa)—while maintaining compliance with the strictest security standards.
Heap vs. Amplitude vs. Pendo: how they measure up
Now you know what autocapture should ideally enable you to do, let’s proceed to the main event: comparing 3 leading analytics solutions that offer autocapture.
At this point, we should note this article is about to deep dive into how these 3 solutions compare in terms of the autocapture they offer, and nothing else.
Autocapture is a critical point of comparison, but for a more comprehensive comparison of Heap, Amplitude, and Pendo (and other solutions including Google Analytics, Fullstory, and Mixpanel) head to our competitor page.
Before we drill down into each solution, here’s a brief overview of how they stack up.
True autocapture (Web)
✅
None
⚠️ Limited (Features only)
Mobile autocapture
✅
⚠️ Lifecycle only (only the basics: app opens/closes/sessions), real product usage data needs to be defined/tracked manually
⚠️ Screen and feature views (not scroll depth/input fields/rage clicks/time on screen, unless approximate), interactions with non-visual/dynamic elements
Manual capture
✅
✅
✅
Retroactive event tracking
✅ full event history
X
⚠️ Partial (feature tagging)
Automatic data labeling
✅
X
X
Visual labeling through a live visual UI
✅
X
✅
Tag-free setup
✅
X Requires code
✅ For feature tagging
Notes
The most comprehensive autocapture, with all events autocaptured, enabling deep retroactive analytics.
Needs explicit software development kit (SDK) configuration for full coverage.
Good coverage, but tagging needed for analysis. Less granular than Heap.
Amplitude
Our first contender is Amplitude. One of the most popular digital analytics platforms out there, Amplitude provides businesses with self-service visibility into the entire customer journey so they can enhance their user experiences and drive growth.
A comparative late comer to autocapture (having previously argued against it), Amplitude now includes both manual and automatic data capture, having recognised that offering both enables its customers to take a more comprehensive approach to data analytics.
Amplitude’s autocapture is enabled via the company’s browser SDK, and lets users automatically collect a predefined set of events and properties in a standardized taxonomy.
Overall, Amplitude’s autocapture could be described as ‘autocapture lite’, with the platform’s main strength remaining in manual tagging (which they call ‘precision tracking’).
That said, if you’re not worried about autocapture being less comprehensive by default, Amplitude has a lot to offer.
Let’s run through some pros and cons.
👍 Amplitude pros
Captures data cross web and mobile
Amplitude offers cross-platform autocapture for your website, enabling you to track basic web and mobile interactions such as page views, clicks, basic form interactions, file downloads, marketing attribution, and basic element interactions.
It also offers limited autocapture for iOS and Android, capturing application installs and upgrades, sessions, and screen views.
Visual labeling for non-technical users
Non-technical users can quickly create events in Amplitude by clicking on specific elements on site, without needing to understand the site’s structure.
For example, if you launch a new landing page and want to see how many people clicked the sign-up button at the top, you can click on that button within Amplitude, label (therefore create) an event, and analyze the data from the date the page launched (assuming the sign-up button was tagged upon implementation).
Precision and customizable tracking for flexibility
When you want to drill deeper into specific events that require additional metadata, or track some events (like a purchase event) that may be core to your business, Amplitude lets you perform manual (‘precision’) tracking.
This means you define a tracking plan and instrument each event to specifically fit your business needs, desired analyses, and for optimal governance.
Tracking with Amplitude is also customizable, meaning that you can selectively enable (and disable) autocapture features.
Robust data governance (including data warehouse syncing)
Amplitude has excellent data governance, giving users a range of tools to help monitor and govern their data and create and maintain event taxonomies. Amplitude doesn’t automatically label data, but as long as you manually define what you care about, the platform will give you precise, clean event data.
What’s more, with Amplitude you don’t have to worry if your data is in sync with your data warehouse (if that data warehouse is either Snowflake or Databricks).
Amplitude’s Data Mutability capability continuously monitors your data warehouse for any modifications. When it detects a change, it automatically updates the corresponding data within the Amplitude platform. With just a few clicks you ensure your analytics aligns with your source of truth.
Strict security measures
Amplitude’s default settings are designed to help businesses adhere to privacy and security requirements. Autocapture won’t capture end-user inputs and has safeguards in place to help you exclude certain sensitive information that may appear on your page.
Plus, as already mentioned, tagging in Amplitude is highly customizable, so you can turn specific autocapture events on and off and only capture clicks on particular element types or pages—all of which is useful for maintaining compliance.
⚠️ Amplitude cons
Autocapture is limited (particularly on mobile)
It’s important to note that Amplitude doesn’t support automatic capture of all web interactions out of the box. A lot of tracking needs to be explicitly requested from, and implemented by, devs.
On mobile, automatic tracking is mostly limited to lifecycle and screen views—more ‘custom’ interaction event tracking has to be implemented.
This presents you with all the aforementioned issues with manual tagging: a time and resource-consuming obligation to maintain and update tracking, and unavoidable holes in your data.
While Amplitude does let you capture basic interaction data, you won’t be able to capture more complex events, such as
Field-level form interactions (input changes, checkbox toggles, error validation states)
Scrolls (how far down the page a user has scrolled)
Hover events
Rage clicks (users rapidly and repeatedly clicking on an element, indicating frustration)
Page visibility
Error tracking
Non PII keystrokes
Custom event properties like Button Text, CSS class
Also, when it comes to the mobile experience, Amplitude doesn’t track native gestures like pinch-to-zoom. So if you’re after a granular view of your mobile web (and app) experience, you’ll want to look elsewhere.
No retroactive tracking
This is a big issue. With Amplitude, you need to decide which events to track upfront, because you can’t go back and retroactively analyze events that weren’t explicitly tracked initially.
In other words, if you overlooked a key event when you implemented Amplitude (or implemented a new feature or element to your product), you’ll have lost all the data on that event up until the date you decided to start capturing it.
Warehouse dependency
The flipside of Amplitude’s Data Mutability is that it makes you dependent on a connective data warehouse for retroactive updates. This adds infrastructure complexity.
Set up is lengthy, laborious, and costly
Depending on how complex your needs are, Amplitude can take up to 6 months to implement.
Plus, to fully activate Amplitude's autocapture capabilities you need to explicitly set up your SDK, increasing your engineering overhead.
Pendo
Pendo is a software experience management platform which, until recently, was known for its capabilities in enabling in-app support.
It facilitates this support with pop-ups that provide app users with guidance, alerting first-time users to features within your app and returning users to new features when they appear.
If your main focus is adding this sort of guidance to your app experience, Pendo is a great option. But when it comes to automatically capturing the full nuances of user behavior across web, mobile and app? Not so much.
But let’s start with the positives…
👍 Pendo pros
Retroactive feature tracking
Once the Pendo snippet is installed, it autocaptures page views and feature usage (button clicks, navigation), so long as those elements exist in your product’s user interface (UI).
Retroactive analytics automatically collect every feature click, and every screen and page load, all without tracking code. Pendo users can identify what to track with a simple point-and-click interface.
No code tagging
You don’t need to be a coder to use Pendo. Anybody can tag buttons or features after the fact by using a simple interface (similar to Heap’s Event Visualizer).
❌ Pendo cons
Captures only feature-based interactions
Pendo isn’t designed for deep product analytics, but more for high-level feature usage.
As a result, Pendo does not capture all user interactions. Interactions like scrolls, rage clicks, field-level behaviors, or failed interactions are all missed.
Limited data governance
Pendo doesn’t automatically label data, so you’ll have to go in and label them yourself. It can be hard work identifying how events are labeled, which events are labeled correctly, and so on.
Limited retroactivity
Despite marketing claims, Pendo doesn’t offer full retroactive behavioral analysis. You can tag features post hoc, but only if they were visible to the user (i.e. not in a hidden tab) during their session. If it wasn’t visible on their screen during their session it won’t be captured.
If you didn’t decide what events to track beforehand, you’ll get no data on them.
Doesn’t track sessions
Pendo doesn’t track sessions, only events. This means you can’t identify the same user across multiple sessions (as you can with Heap).
Heap
Yep, we saved the best until last. Heap is a digital insights platform that gives you complete understanding of your customers’ digital journeys.
To enable this, Heap offers truly comprehensive autocapture (which we call Smart Capture) with tag-free set up.
A single snippet of code captures all user interactions in your product (across mobile and web), including clicks, swipes, taps, page views, screen views, form fills and sessions—from the moment of installation onwards.
Once captured, that behavioral data has unlimited retroactivity, meaning you can define, redefine, and analyze historical data in any way you see fit. (For example, by creating funnels for interactions that were captured months prior.)
Plus, you can enrich your autocaptured dataset with client and server-side events using our platform’s flexible APIs.
👍 Heap pros
Comprehensive cross-device capture
Smart Capture makes it easy to capture cross-platform data—spanning web, native mobile, hybrid, and more.
Heap’s mobile SDKs are reliable, requiring less code than other solutions. Frameworks covered include:
iOS SwiftUI
iOS UIKit
Android View
Android Jetpack
React Native
Flutter
Xamarin
Ionic
Cordova
Capacitor
Implementation is quick and easy, and maintenance work is a fraction of other tools.
Easy set up
You can easily install Heap on any modern framework or device. It works on web, iOS, Android, and an ever growing list of third-party applications.
There’s no need for any pre-configuration or engineering, either. Just enter the Heap snippet and Smart Capture will start tracking everything.
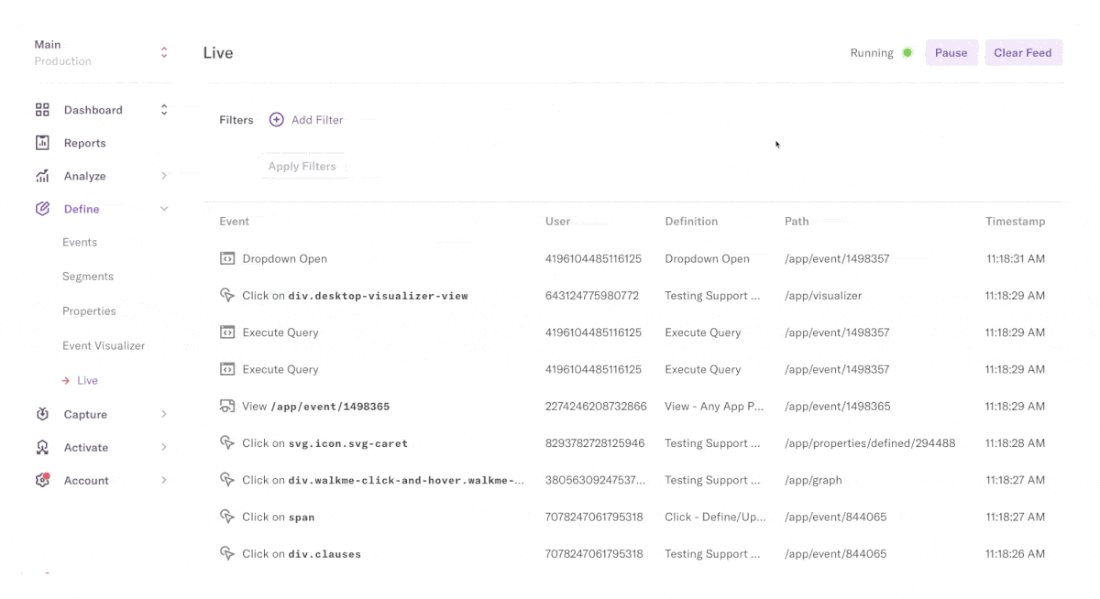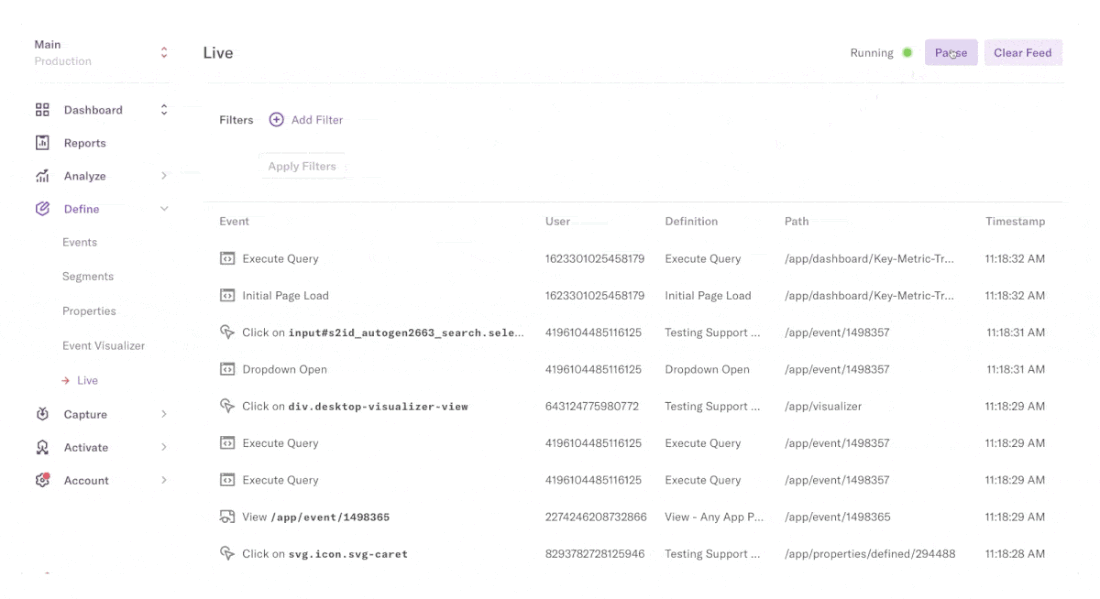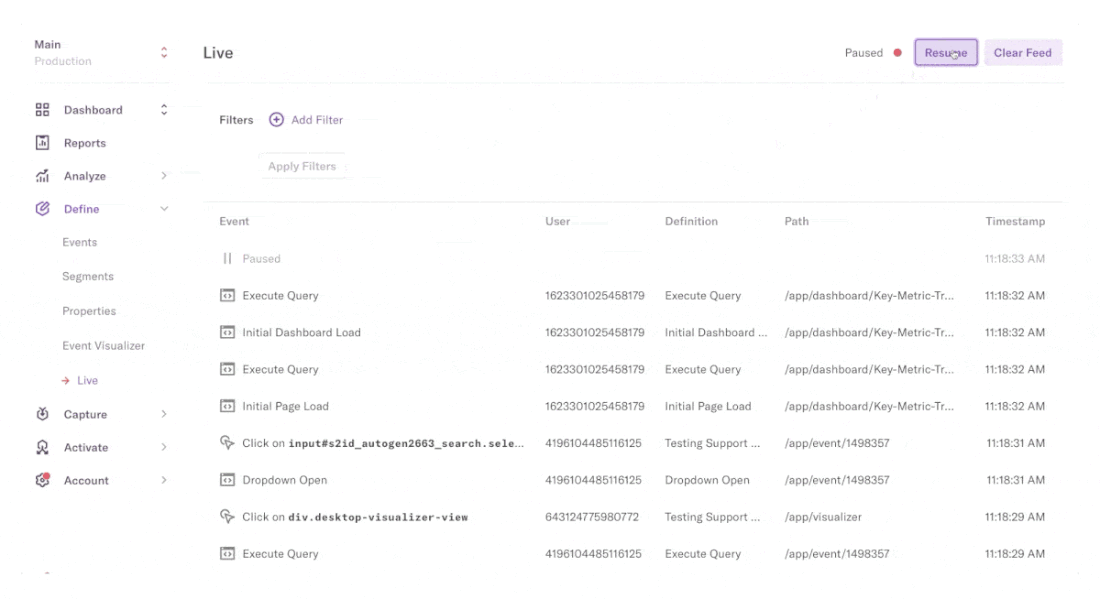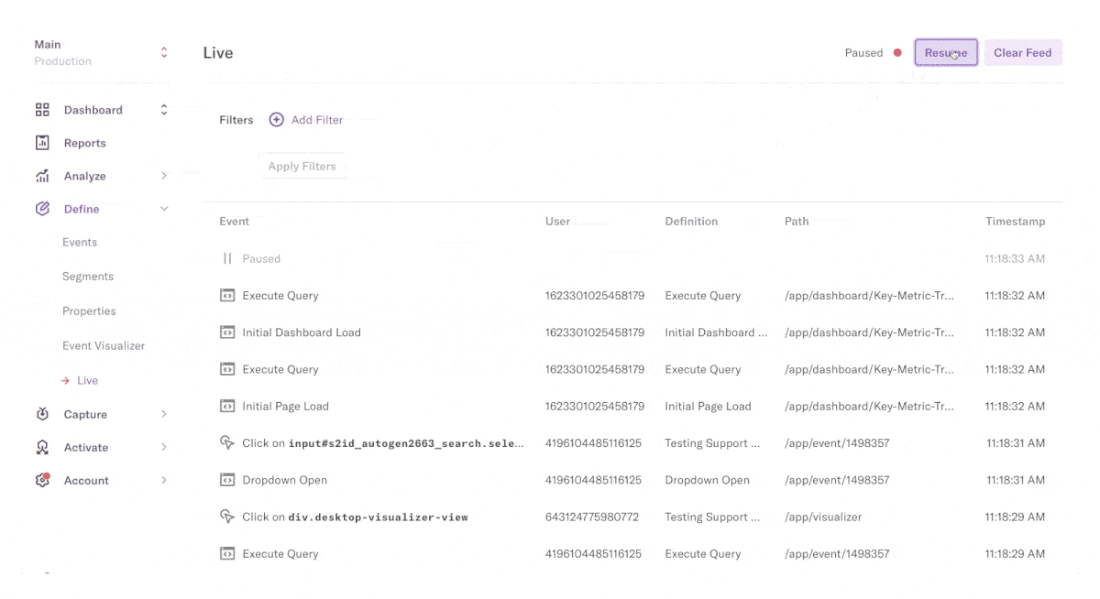
Heap tagging events automatically
A fully retroactive dataset
No more saying (or crying out with your head in your hands) “I wish we’d thought of tagging that”.
With Heap, you have a complete and pristine set of raw interaction data from the date you installed it that you can dig through and analyze in any way you want. (Heap even helps you keep it pristine by automatically flagging and helping you to repair broken event definitions.)
Surface what matters (and forget what doesn’t)
At this point, you might be thinking: “So it captures everything? That’s great, but how are we going to deal with all that data? And how are we going to find the insights we need?”
No need to worry: all the raw data that Heap captures sits quietly under the surface, out of view, waiting to be called into action. You won’t even notice it’s there—until you need it.
Until events are ‘defined’ by you in Heap, they can’t be analyzed. This keeps most data out of sight and mind, avoiding overwhelm and confusion.
When you need a data point, it’s easy to find. You simply use Event Visualizer to create a virtual event—a human-readable name that points to underlying data (virtual events are the units of analysis used in Heap reporting).
You don’t need to ask and wait for an engineer to create virtual events. Anybody can do it, using Heap’s point-and-click user interface.
Create events with a single click using Heap's Event Visualizer
Crucially, any modifications you make to the event (such as altering the event criteria or combining multiple events together) will apply to data retroactively.
Flexibility to complement autocapture
While Heap Smart Capture captures 100% of behavioral events, it by no means restricts you to autocapture. With Heap, you can choose your own path when it comes to labeling and bucketing events, and create and manage custom events on your own infrastructure with ease.
There are various types of data Heap doesn’t autocapture for security reasons. This includes sensitive information such as payments processes, and ‘custom properties’ that provide extra information about the user (such as their role or name), or event (such as dollar value).
Heap APIs give you the flexibility to supplement and enrich your autocaptured data with these manually tagged and labelled events.
Update events with ease
Heap’s autocapture is built with rapid and constant iteration in mind. However often you iterate new features, autocapture is collecting events in the background—and will let you know when you need to replace obsolete events with new ones.
Note: replacing old events doesn’t mean losing old data. Using combo events, you can combine features from your product’s older versions with new features and track them as single events.

Track multiple events under a single ‘combination event’ umbrella
Capture behavioral data without compromising on security

Heap is built with privacy in mind, and is compliant with SOC 2 Types 1 and 2 and GDPR (among others). So it makes sense we’ve put intentional limits on our autocapture to avoid putting you (and your users) at risk.
Out of the box, Heap only tracks that interactions have happened. It doesn’t track anything about the users who perform those interactions, or anything sensitive about the interactions themselves.
For example, if a user enters their social security number on your website, Heap will automatically track that something was typed into the field, but will not capture what was typed in.
Using APIs, you can proactively decide to send relevant, non-sensitive user level data to Heap, in a process managed by the admin user on the account.
❌ Heap cons
No bi-directional warehouse sync
Heap lacks Amplitude’s Data Mutability feature for bidirectional data corrections.
However, Heap Connect does make it easy to ensure your behavioral data is synced to your warehouse, even retroactively.
With the flick of a switch, you can send behavioral data to your cloud data warehouse (including Redshift, BigQuery, Snowflake, or S3) with a managed ETL.
Heap Connect lets you
Automatically models behavioral data in a user-centric schema
Resolves identities across devices and platforms
Sessionizes in-product behavior
There’s a learning curve
Teams must adapt to Heap’s virtual event system to unlock its full potential. (However, we’d argue that it’s pretty intuitive, and we offer a complete course in creating event definitions for anybody who needs to learn.)
Labeling overhead
While Smart Capture collects all the rich behavioral data you need automatically, teams still need to invest some time in organizing and labeling events to unlock insights. That takes time—but is still far faster and more scalable than manual tagging.
Note: Heap automatically assigns default names to captured events based on element attributes. You can rename these events anytime to match your team’s naming conventions.
Perceived data overload
Teams unfamiliar with Heap’s virtual events may feel overwhelmed by the volume of raw data, though it’s stored unobtrusively—and only becomes visible when labeled.
Heap’s autocapture is better. (We can show you.)
This probably won’t come as news to you (this being the Heap website and all), but we believe that for many of the companies out there who want to capture and analyze their behavioral data, Heap is the best option.
Some analytics solutions will only automatically capture some of the events it can track, not letting you go back to capture events you’ve figured out you should’ve been tracking all along.
Other solutions can only capture a small, relatively superficial range of interactions, and can’t sessionize data. As a result, you’ll not be able to understand how people are using your product, what’s engaging them, and what’s putting them off.
Heap, by contrast, captures absolutely every interaction and event you could ever want to analyze, from the moment you install it—and lets you go back and analyze those events whenever you need to.
So if you want to make sure you’re capturing everything you need to know about how your users are using your product, Heap is the solution for your business.
But of course we would say that.
Why not find out if we’re right? Book a demo with one of our experts today and we’ll show you how Heap captures your data—and turns it into analytics gold.
Make everybody a data analyst with Heap
Heap’s AI-powered data analytics makes data analysis easy, fast, and impactful. Request a demo to see for yourself.
Getting started is easy
Interested in a demo of Heap’s Product Analytics platform? We’d love to chat with you!